Sidebar
en:data
This is an old revision of the document!
Table of Contents
Combination of pedestrian detectors
We provide the MATLAB® code for our evidential combination of pedestrian detectors.
To make the code work, you will need to download the Matlab evaluation/labeling code provided by the Caltech Pedestrian Detection Benchmark and Piotr's Matlab Toolbox. Copy the dbFusion.m file in the same directory as the dbEval.m file and simply run it. To divide the UsaTest dataset into a validation and testing set, add the following line to dbInfo.m:
case 'usaval' % Caltech Pedestrian Datasets (validation)
setIds=6; subdir='USA'; skip=30; ext='jpg';
vidIds={0:18};
case 'usatest2' % Caltech Pedestrian Datasets (testing sub set)
setIds=7:10; subdir='USA'; skip=30; ext='jpg';
vidIds={0:11 0:10 0:11 0:11};
Download
| Link | |
|---|---|
| Combination code | dbfusion.zip |
| Caltech evaluation code | Link |
| Piotr's Matlab Toolbox | Link |
References
Ph. Xu, F. Davoine and T. Denoeux. Evidential Combination of Pedestrian Detectors. In Proceedings of the 25th British Machine Vision Conference (BMVC), Nottingham, UK, September 1-5, 2014. paper oral
KITTI semantic segmentation ground truth

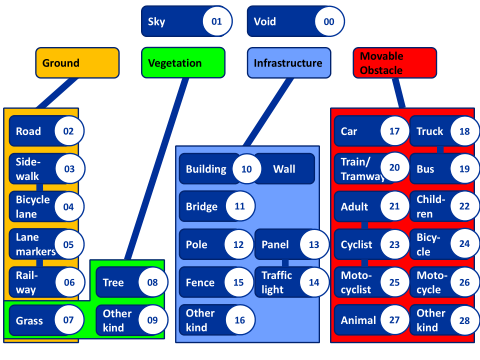 A set of 107 images (70 for training and 37 for testing) from the KITTI Vision Benchmark Suite were manually annotated with the software Adobe® Photoshop® CS2.
The left color images were annotated at the pixel level considering a set of 28 classes.
A set of 107 images (70 for training and 37 for testing) from the KITTI Vision Benchmark Suite were manually annotated with the software Adobe® Photoshop® CS2.
The left color images were annotated at the pixel level considering a set of 28 classes.
Download
| Training set | Testing set | |
|---|---|---|
| Ground truth | gttrain.zip | gttest.zip |
| Left images | lefttrain.zip | lefttest.zip |
| Right images | righttrain.zip | righttest.zip |
| Velodyne data | velotrain.zip | velotest.zip |
For convenience, we also provide the left and right images, as well as the Velodyne data, associated to the ground truth annotations. These data were extracted from the raw sequences. They are copyright by the KITTI Vision Benchmark Suite and published under the Creative Commons Attribution-NonCommercial-ShareAlike 3.0 License.
References
Ph. Xu, F. Davoine, J.-B. Bordes, H. Zhao and T. Denoeux. Multimodal Information Fusion for Urban Scene Understanding. Machine Vision and Applications (MVA), in Press, 2014.
Ph. Xu, F. Davoine, J.-B. Bordes, H. Zhao and T. Denoeux. Information Fusion on Oversegmented Images: An Application for Urban Scene Understanding. In Proceedings of the Thirteenth IAPR International Conference on Machine Vision Applications (MVA), pages 189-193, Kyoto, Japan, May 20-23, 2013. paperoral HAL
KITTI moving object segmentation ground truth
Coming soon…
Page Tools
en/data.1419420727.txt.gz · Last modified: 2014/12/24 12:32 by xuphilip